

启明创投管理合伙人周志峰近日在与美国AI社区沟通过程中,听到OpenAI的GPT-5或将推迟到2025年底的消息。原因之一或许是用于大模型训练的13万亿数据仍不够,为此OpenAI不得不无奈地用同样的数据“重新训练”。但如果有更多优质私域多维数据供给,大模型的表现还是可以有新的飞跃的。
另一边,在上海洋山四期自动化无人码头,吊车司机坐在百里之外的操控室里“远程提箱”,但每天产生的遥控集装箱运动数据却没有被采集。在上海过程智能制造公司董事总经理何仁龙看来,这些白白流失的数据,对大模型来说是非常有用的语料,如果将其输入大模型,进行训练,未来集装箱真正实现无人化有望。

桥吊司机“远程拿箱”
一种是“想要而得不到”的焦虑,一种是“白白浪费”的叹息。
大模型就像一个“数据饥渴怪兽”,除了追求数量,对质量也是挑剔的,就像一个没有条件接受优质教育的孩子,未来无从谈起高质量的输出,大批量的高质量语料库是国内外大模型的共同愿望。
大模型最头疼的问题之一,就是数据异构、质量参差不齐,犹如一锅“炖肉”。 “如果把所有数据都放到一张表里,机器学习的门槛就会大大降低。”但这只是中科院院士欧伟南的美好愿望。事实是,大模型训练过程中面对的知识和推理类型繁多,包括数字、文本、图片、语言、视频等。这不仅让大模型“眼花缭乱”,还容易导致大模型规模呈指数级增长,大量无用数据被占用,造成干扰,拖累效率,降低准确率。
欧伟南认为数据库技术是发展下一代AGI(通用人工智能)的关键,并高度评价了全球首个AI数据库MyScale数据库。该数据库刚刚获得2024WAIC硬核奖SAIL奖,能够在同一系统内支持海量结构化、向量、文本、时序、图片等异构数据的高效存储和联合查询。他认为这是目前全球综合性能最好、功能最强大的AI数据库。

欧伟南点赞全球首个AI数据库——MyScale数据库
“MyScale数据库技术的一个成功案例是,我国在北京和上海各有一个公安部指纹中心,每个中心管理着20多亿枚指纹。现在指纹照片入库后可以立即比对,几秒钟就能出结果。”鄂伟南补充道:“关键是省钱,公安部规划两个中心时,一期准备了10亿元的项目资金。但有了MyScale数据库技术,只用了几百万元就解决了问题,而且一步到位,不用建二期、三期。”
鄂维南把这条技术路线称为“穷人版技术路线”,旨在避免大模型臃肿、浮夸。他还认为,不同使用频率的知识应该分层,并提出了“记忆立方体”的建模目标。鄂维南把非思考、条件反射的内隐记忆、需要推理、起草的工作记忆以及各类专业知识“分开处理”,将高频数据“构建”进大模型,同时“外挂”专业知识,确保知识的训练和读取能够实现最小成本。
“这涉及到大模型底层架构、训练框架等的深度改进。但在上海市政府、临港新片区管委会、上海市经信委的支持下,我们落实了这条技术路线,把大模型体积缩小了十倍。”鄂伟南自豪地说。
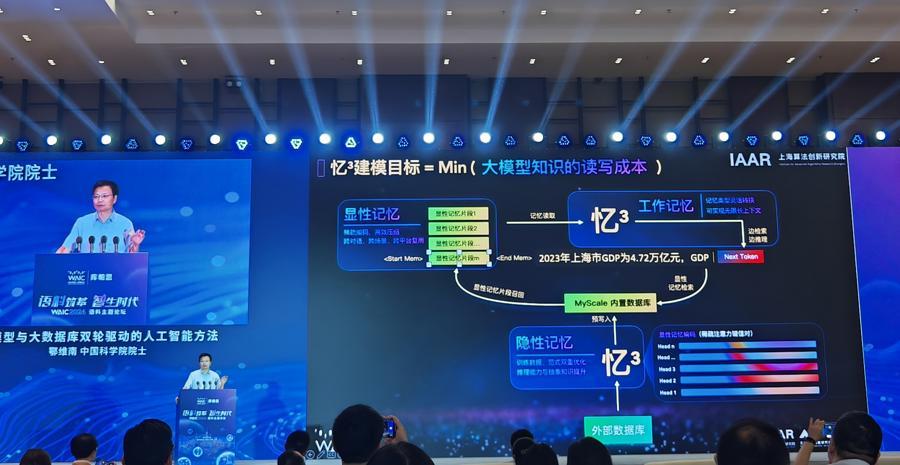
“记忆立方体”的建模目标
大模型的另一大痛点,是大量优质数据被锁在抽屉里,得不到共享甚至收集。上海捷越星辰智能科技有限公司副总裁李静甚至抛开算力不足、专业人才匮乏等困难,将数据语料不足称为“基础模型与行业应用之间最大的差距”。
何仁龙也着急,他列举的洋山四期自动化码头远程抓箱动作数据就是高价值的行业数据。“这跟马斯克训练人形机器人‘擎天柱’进行电池组装的逻辑一模一样。如果把更多分散在各个制造业领域的专业数据收集起来,用来训练大模型,未来就能形成机器人操作的SOP(标准作业流程),让传统制造业焕然一新。”

特斯拉人形机器人擎天柱
事实上,政府、产业等各方都已采取行动,统一数据,增加供给。
据记者了解,一年前,在2023世界人工智能大会开幕式上,由上海人工智能实验室、上海文广集团、中国科学技术信息研究所等10家单位共同发起的中国大模型语料数据联盟宣布成立。联盟几乎囊括了全国及上海语料数据供给的主力军和排头兵。去年8月14日,联盟发布成果——“学海万卷”多模态预训练语料,总数据量超过2TB(兆兆字节)。这2TB数据经过严格筛选,质量上乘,发布两周内下载量已达18万次,创下我国大模型全面兴起后公开发布的单一数据集下载量最大的纪录。
在7月6日举办的2024世界人工智能大会“语料筑就智能生活时代基石”语料主题论坛上,上海级语料公司库博联合大模型语料生态伙伴发布了一批大模型语料成果,包括语料运营平台1.0上线、首批十款优质语料产品发布等。
其中,语料运营平台1.0实现了语料数据的“采集、清洗、标注、检测、使用”五位一体的工具链能力。

语料运营平台1.0上线
此外,库博还联合咪咕视讯、宝信软件、复旦大学智能医疗研究院、上海产业创新中心、汇纳科技、万达信息等发布十大语料数据产品,旨在提升供给侧能力,加速推动医疗健康、城市交通、消费零售、金融、音视频等重点行业规模化模型产业发展。
语料库体系建设需要规则与实践并行,本次论坛还发布了语料库建设指南、金融、生命健康、教育等行业语料库技术白皮书、语料库生态服务模式可持续发展倡议。
本次主题论坛由大模型语料数据联盟、上海酷帕斯科技有限公司、上海市数字商业协会、上海文化广播电视台等联合主办。
